Shell 三剑客是 grep 、 sed 和 awk 三个工具的简称,因功能强大,使用方便且使用频率高,因此被戏称为三剑客。三者均用于处理文本,但各自侧重点不同。
| 剑客 | 特长 |
|---|---|
| grep | 查找、匹配文本,仅筛选不修改 |
| sed | 文本替换、删除、插入,常用于自动化处理任务 |
| awk | 复杂计算、格式处理 |
# grep
# 基础语法
grep [选项] "模式" [文件...] |
# 常用选项
-i:忽略大小写进行匹配。-v:反向查找,只打印不匹配的行。-n:显示匹配行的行号。-r:递归查找子目录中的文件。-l:只打印匹配的文件名。-c:只打印匹配的行数。-E: 启用扩展正则表达式
如果不指定任何选项的话,将直接输出所有包含搜索模式的行,不显示其他信息(如行号、文件名等);
如果指定多个选项,直接合并即可,如 grep -in "hello" file.txt
# 模式
可以是以下三种:
- 普通字符串
- 基础正则表达式
- 扩展正则表达式(选项需要有
-E)
# 实用示例
下图是 helloworld.c 文件的内容
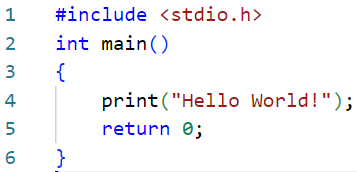
grep -in "hello" helloworld.c作用:不区分大小写、显示行号,查找
helloworld.c中的“hello”输出:
4: print("Hello World!");grep -ci "hello" helloworld.c作用:不区分大小写,统计
“hello"出现次数输出:
1grep -E "\(.+\)" helloworld.c作用:启用扩展正则表达式,匹配内容
输出:
print("Hello World!");cat helloworld.c | grep -v "print"作用:管道结合,过滤含有
print的行输出:
#include <stdio.h>int main()
{return 0;
}
# sed
sed 是一种流编辑器,它是文本处理中非常适中的工具,能够完美的配合正则表达式使用。处理时,把当前处理的 ’行‘ 存储在临时缓冲区中,又称为 ‘模式空间’(pattern space) ,接着使用 sed 命令再去处理缓冲区中的内容,处理完成后,把缓冲区的内容输出到屏幕上,接着再去处理下一行,这样不断重复,知道处理到文件的末尾,文件内容并没有改变(也可以指定选项,直接修改文件)
# 基础语法
sed [选项] '命令' [文件]
# 常用选项
sed 默认输出文件的全部内容,并且不会对原文件作修改
-n: 只输出匹配到的内容,这个选项一般只用于查看-i: 直接修改原文件内容-r: 支持扩展正则表达式-e: 匹配多个命令
# 常用命令
<行号>a<内容>: 新增,在行号后新增一行相应内容。行号可以是 “数字”,在这一行之后新增,也可以是 “起始行,终止行”,在其中的每一行后新增。当不写行号时,在每一行之后新增。使用$表示最后一行。后面的命令同理。<行号>c<内容>:取代。用内容取代相应行的文本。<行号>i<内容>:插入。在当前行的上面插入一行文本。<行号>d:删除当前行的内容。<行号>p:输出选择的内容。通常与选项-n一起使用。s/<re>/<string>/:将 <re>(正则表达式)匹配的内容替换为 < string>。
# 实用示例
sed -n '3p' my.txt
# 输出 my.txt 的第三行sed '2d' my.txt
# 删除 my.txt 文件的第二行sed '2,$d' my.txt
# 删除 my.txt 文件的第二行到最后一行sed 's/str1/str2/g' my.txt
# 在整行范围内把 str1 替换为 str2。# 如果没有 g 标记,则只有每行第一个匹配的 str1 被替换成 str2sed -e '4astr ' -e 's/str/aaa/' my.txt
# -e 选项允许在同一行里执行多条命令。例子的第一条是第四行后添加一个 str,# 第二个命令是将 str 替换为 aaa。命令的执行顺序对结果有影响。注意,以上的例子并不会真正修改
my.txt中的内容。若想修改,需要添加-i选项将
src.txt的第 2、4、8、16、32 行的内容提取到result.txt中:sed -n '2p;4p;8p;16p;' src.txt > result.txt
# awk
awk 是最复杂的剑客,它不仅仅是工具软件,还是一种微型编程语言。它逐行读取输入文件(或标准输入),根据分隔符,将该行划分成各个字段(列),存入 $1 、 $2 、 $3 ・・・・中去。然后按指定的规则处理并输出结果。
# 基础语法
awk [option] 'pattern { action }' file |
# 参数说明
options:是一些选项,用于控制awk的行为。pattern:是用于匹配输入数据的模式,如\regex\、NR == 1、BEGIN(在文件处理前)、END(在文件处理后)。如果省略,则awk将对所有行进行操作。{action}:是在匹配到模式的行上执行的动作。如果省略,则默认动作是打印(print)整行。
# 常用内置变量
| 变量 | 说明 |
|---|---|
$0 | 当前整行内容 |
$1, $2, ..., $N | 第 1, 2, ..., N 列(默认以空格或制表符分隔) |
NF | 当前行的列数 |
NR | 当前行号 |
FS | 输入字段分隔符(默认空格) |
OFS | 输出字段分隔符(默认空格) |
FILENAME | 当前处理的文件名 |
# 自定义变量
有两种方式:
-v var=value(区分字符的大小写)如
awk -v test='hello' 'BEGIN {print test}'在
{ action }中定义如
awk 'BEGIN {test='hello' print test}'
# 实用实例
打印整行:
awk '{print}' file
打印特定列:
awk '{print $1, $2}' file
使用分隔符指定列:
awk -F',' '{print $1, $2}' file
打印行数:
awk '{print NR, $0}' file
打印行数满足条件的行:
awk '/pattern/ {print NR, $0}' file
计算列的总和:
awk '{sum += $1} END {print sum}' file
打印最大值:
awk 'max < $1 {max = $1} END {print max}' file
格式化输出:
awk '{printf "%-10s %-10s\n", $1, $2}' file
# Lab0 实践
sed:![image-20250313160725790]()
![image-20250313160740518]()
#!/bin/bash# 获取输入参数SOURCE_FILE=$1
TARGET_FILE=$2
# 提取指定行的内容并写入目标文件sed -n '8p;32p;128p;512p;1024p' "$SOURCE_FILE" > "$TARGET_FILE"
sed、awk:![image-20250313160920400]()
#!/bin/bashpattern=$2
sed -n "/$pattern/=" $1 > $3
#!/bin/bashfilea=$1
pattern=$2
fileb=$3
awk -v pat="$pattern" 'index($0, pat) {print NR}' "$filea" > "$fileb"
sed:![image-20250313162423931]()
#!/bin/bashFILE=$1
SRC=$2
DST=$3
sed -i "s/$SRC/$DST/g" "$FILE"




# 参考资料
whisper_hm - 博客园
三剑客 - CSDN 博客
菜鸟教程